这两天啊,各地高考的获利终于是络续公布了。
当今,亦然时辰揭晓全球第一梯队的大模子们的“高考获利”了——
咱们先来看下合座的情况(该测试由字节向上Seed团队官方发布):
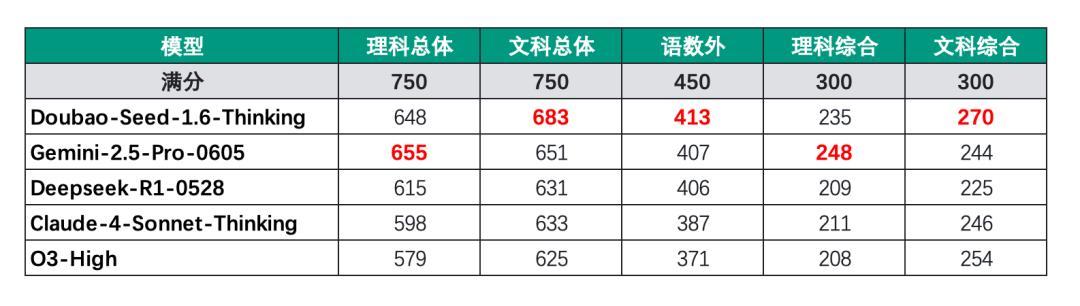
按照传统文理分科计分心志,Gemini的理科总获利655分,在悉数选手里排名第一。豆包的文科总获利683分,排名第一,理科总获利是648分,排名第二。
再来看下各个细分科联想获利情况:
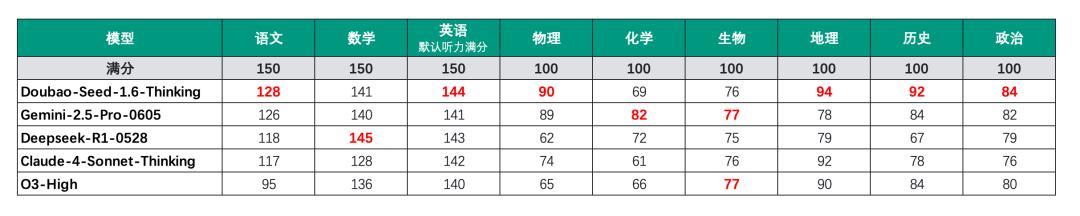
除了数学、化学和生物除外,豆包的获利依旧是名列三甲,6个科目均是第一。
不外其它AI选手的推崇亦然比较可以,可以说是达到了优秀学生的水准。
比较缺憾的选手就要属O3,因为它在语文写稿上跑了题,因此语文获利仅95分,拉低了合座的分数。
要是从填报志愿角度来看,因为这套测试经受的是山东省的试卷,阐发过往教育判断,3门自选科联想赋分比较原始分会有一定进程的提高,尤其是在化学、物理等难度较大的科目上。本次除化学获利相对稍低外,豆包的其余科目组合的赋分获利最高能超越690分,有望冲刺清华、北大。
(赋分礼貌:将考生选考科联想原始获利按照一定比例辨别品级,然后将品级休养为品级分计入高考总分)
好,那当今的豆包濒临的抉择是:上清华照旧上北大?

大模子参加高考,分数何如判?
在看完获利之后,好像许多小伙伴皆有疑心,这个评测获利到底是何如来的。
别急,咱们这就对评测法式逐条领会。
领先在卷子的选择上,由于目下收罗流出的高考真题皆诟谇官方的,而山东是少数传出全套考卷的高考大省;因此主科(即语文、数学、英语)经受的是本年的宇宙一卷,副科经受的则是山东卷,满分预料750分。
其次在评测神志上,皆是通过API测试,不会联网查询,评分流程亦然参考高考判卷神志,就是为了测验模子自己的泛化才气:选择题、填空题经受机评(自动评估)加东说念主工质检的神志;灵通题践诺双评制,由两位具有联考阅卷教育的要点高中教师匿名评阅,并开拓多轮质检门径。
在给模子打分的时辰,经受的是 “3门主科(语文数学英语)+3门概述科(理综或文综)” 的总分狡计神志,给五个模子排了个排名。
值得一提的是,通盘评测流程中,模子们并没灵验任何指示词优化手段来提高模子的推崇,举例条件某个模子回话得更详确一些,或者刻意线路是高考等等。
终末,就是在这么一个公道公正的环境之下,从刚才咱们展示的限制来看,Gemini、豆包相对其他AI来说获得了较优的获利。
细分科目推崇分析
了解完评测法式之后,咱们连接深切解读一下AI选手们在各个科目上的推崇。
由于深度念念考的大火,大模子们在数学这么强推理科目上的才气昭着要比昨年好许多(此前大部分均不足格),基本上皆能达到140分的获利。
不外在一说念不算难的单选题(宇宙一卷第6题)上,国表里的大模子们却皆栽了跟头:
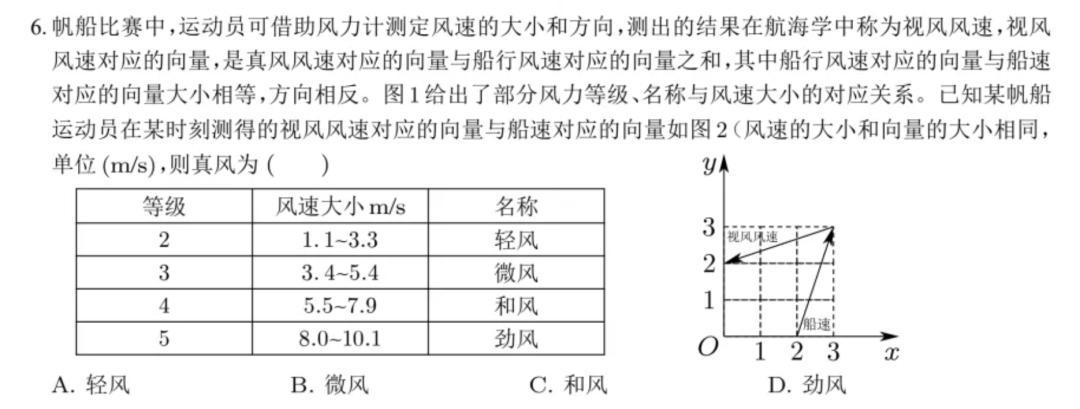
这说念题大模子们给出的谜底是这么的:
豆包:C;Gemini:B;Claude:C;O3:C;DeepSeek:C。
但这说念题的正解应该是A,因此大模子们在此杜渐防萌。
之所如斯,主要是因为题目里有方框、虚线、箭头和汉字混在全部的图,模子认不准图像,线路它们在 “看图言语” 这块还有进步空间。
以及在更难的压轴大题上,许多大模子也没宽裕拿下,往往漏写讲解流程,或者推导不严谨被扣分,线路在细节上还需加强。
到作念语文华用题和阅读题这两个版本,大模子们确切是 “学霸本霸”,得分率超高。
不外在作文写稿流程也暴泄漏了一些问题,举例写稿过于刻板、笔墨冰冷,著作字数不达标(不足800字或超越1200字)、立意分歧,情景上还往往会出现习用的小标题。

在英语测试流程中,大模子们确切挑不出舛讹,独一扣分点是在写稿上,比如用词不够精确、句式稍显单调,但合座也曾很接近无缺。
关于理综,际遇带图的题目大模子们照旧会犯难,不外豆包和Gemini这俩模子在看图像和通晓图的才气上会比其他模子强一些。
举例底下这说念题中,正确谜底应当是C,大模子们的作答是这么的:
豆包:C;Gemini:C;Claude:D;O3:D;DeepSeek:D。

终末在文综方面,大模子的地域离别就显现得比较昭着,海外的大模子作念政事、历史题时,往往搞不懂题目在考啥,对中国的常识点不太 “伤风”。
而关于地舆题,最头疼的即是分析统计图和地形图,得从图里精确索要信息再分析。
以上就是关于本次评测的全面分析了。
除了本年国内的高考除外,这几位“参赛选手”还参加了印度理工学院的第二阶段入学考试——JEE Advanced。
这场考试每年罕见百万东说念主参与第一阶段考试,其中前25万考生可晋级第二阶段。它分为两场,每场时长3小时,同期对数学、物理、化学三科进行覆按。
题目以图片情景呈现,要点捕快模子的多模态处理才气与推理泛化才气。悉数题目均为客不雅题,每说念题进行5次采样,并严格按照JEE考试礼貌评分——答对得分、答错扣分,不触及情景评分法式。
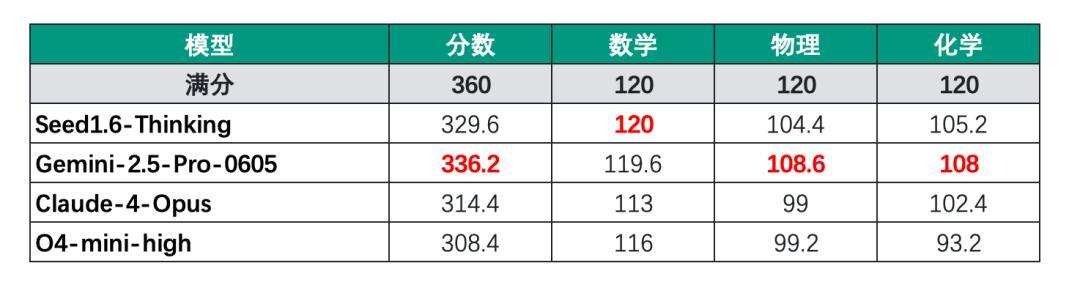
与全印度东说念主类考生获利对比傲气,第又名得分332分,第十名得分317分。
值得刺目的是,豆包与Gemini已具备参加全印度前10的实力:Gemini在物理和化学科目中推崇杰出,而豆包在数学科目5次采样中齐备全对。
何如作念到的?
比较昨年一册线凹凸的水平,合座来看,大模子们在本年高考题上的推崇均有昭着的进步。
那么它们到底是怎么进步才气的?咱们不妨以拿下单科第一最多的豆包为例来了解一下。
豆包大模子1.6系列,是字节向上Seed团队推出的兼具多模态才气与深度推理的新一代通用模子。
团队让它才气进步的时间亮点,咱们可以归结为三招。
第一招:多模态和会与256K长凹凸文才气构建
Seed1.6延续了Seed1.5在衰竭MoE(羼杂巨匠模子)鸿沟的时间积聚,经受23B激活参数与230B总参数范围进行预西宾。其预西宾流程通过三个阶段齐备多模态才气和会与长凹凸文援救:
第一阶段:纯文本预西宾
以网页、竹素、论文、代码等数据为西宾基础,通过礼貌与模子结合的数据清洗、过滤、去重及采样战术,进步数据质料与常识密度。
第二阶段:多模态羼杂捏续西宾(MMCT)
进一步强化文本数据的常识与推理密度,加多学科、代码、推理类数据占比,同期引入视觉模态数据,与高质料文本羼杂西宾。
第三阶段:长凹凸文捏续西宾(LongCT)
通过不同长度的长文数据逐渐推广模子序列长度,将最大援救长度从32K进步至256K。
通过模子架构、西宾算法及Infra的捏续优化,Seed1.6 base模子在参数目范围接近的情况下,性能较Seed1.5 base齐备显耀进步,为后续后西宾职责奠定基础。
这一招的发力,就对诸如高评语文阅读通晓、英语完形填空和理科概述利用题等的作答上起到了提高准确率的作用,因为它们往往触及长文本且垂青凹凸文通晓。
第二招:多模态和会的深度念念考才气
Seed1.6-Thinking 延续Seed1.5-Thinking的多阶段RFT(强化响应西宾)与RL(强化学习)迭代优化门径,每轮RL以上一轮RFT为起头,通过多维度奖励模子筛选最优回话。相较于前代,其升级点包括:
拓展西宾算力,扩大高质料数据范围(涵盖 Math、Code、Puzzle 等鸿沟);
进步复杂问题的念念考长度,深度和会VLM才气,赋予模子清醒的视觉通晓才气;
引入parallel decoding时间,无需相当西宾即可推广模子才气 —— 举例在高难度测试集Beyond AIME中,推理获利进步8分,代码任务推崇也显耀优化。
这种才气平直对应高收用触及图表、公式的题目,如数学几何讲解、物理电路图分析、地舆等高线判读等;可以快速定位要道参数并推导出解题旅途,幸免因单一模态信息缺失导致的误判。
第三招:AutoCoT措置过度念念考问题
深度念念考依赖Long CoT(长念念维链)增强推理才气,但易导致 “过度念念考”—— 生成开阔无效token,加多推理包袱。
为此,Seed1.6-AutoCoT建议 “动态念念考才气”,提供全念念考、不念念考、自相宜念念考三种模式,并通过RL西宾中引入新奖励函数(处分过度念念考、奖励稳当念念考),齐备CoT长度的动态压缩。
在骨子测试中:
中等难度任务(如 MMLU、MMLU pro)中,CoT 触发率与任务难度正磋磨(MMLU 触发率37%,MMLU pro触发率70%);
复杂任务(如AIME)中,CoT触发率达100%,成果与Seed1.6-FullCoT非常,考证了自相宜念念考对Long CoT推理上风的保留。
以上就是豆包能够在本年高考全科目评测中脱颖而出的原因了。
不外除此除外,还有一些影响要素值得说说念说说念。
正如咱们刚才提到的,化学和生物的题目中读图题占比较大,但因非官方发布的图片清醒度不足,会导致多数大模子的推崇欠安;不外Gemini2.5-Pro-0605的多模态才气较杰出,尤其在化学鸿沟。
不外最近,字节Seed团队在使用了更清醒的高考真题图片后,以图文结合的神志重新测试了对图片通晓条件较高的生物和化学科目,限制傲气Seed1.6-Thinking的总分进步了近30分(理科总分达676)。

△图文交汇输入示例
这线路,全模态推理(结合文本与图像)能显耀开释模子后劲,是当年值得深切探索的主义。
那么你关于此次大模子们的battle限制有何办法?接待大家拿真题去实测后体育游戏app平台,在批驳区留言你的感受~